
Sorry it has been so long since our last post.
This has been a very crazy week for me that I can most aptly describe with a quote from Dr. Peter Venkman in Ghostbusters when he described "...human sacrifice, dogs and cats living together - mass hysteria!"
Anyways, I am glad the week is over. We hope to get back to more regular posting again.
While I am admittedly tired of talking about genetics here, I am going to address the subject at least 3 more times in the near future. We have two more posts to go in our State of the Art series and we have the post that I am about to write.
Currently in the news, we are hearing about steps closer to "artificial life". The idea of artificial life is an odd one to me since life can largely be catagorized as a binary state, alive or not alive. It seems difficult to me to be artificially alive. Oh, I know many of you will want to nitpick about grey areas like viruses and such, but that's a completely different question. My bottom line is that life is real or not alive. There will never be artificial life. Ah, the wonders of semantics.
So what am I talking about here? What is the big news? Researchers at the J. Craig Venter Institute in Maryland have published a paper in Science explaining how they transfered an entire genome from one species of bacteria (Mycoplasma mycoides) into a population of a completely different species of bacteria (Mycoplasma capricolum). On the surface, this might seem unremarkable since Dolly the sheep was cloned back in 1996 by transferring the entire genetic code of one sheep into a sheep egg cell. However, up until now, no cells of one species have been made to "engraft" an entirely transplanted genome of another species.
While the idea that this will lead to "artificial life" is somewhat absurd since the concept doesn't really exist, this is exciting because it could be a first step toward creating novel organisms specifically designed for a human need. Imagine a bacteria that could be designed to metabolize sugar and produce propane for fuel. While I am not sure that is an attainable endeavor, Venter seems to think it is. I imagine, to him, this publication is one more step in the right direction. Not sure it is the right direction, but it is definately a step toward his goals.
Saturday, June 30, 2007
Monday, June 25, 2007
Speaking of AAV, Parkinson's Gene Therapy progress?
Considering that we've been talking about gene therapy a lot here lately, I think this news is quite relevant. Current Omnome topics aside, this news is very important.
There have been recent reports about a gene therapy strategy that resulted in symptom amelioration in Parkinson's patients. The project was spearheaded in part by Dr. Matthew During of Ohio State University. Having met Dr. During at the Society for Neuroscience conference in Orlando in 2002, I am not at all surprised that he would be part of a project that could stand at the cutting edge of clinical translational research. As a trained neurosurgeon with a PhD, this New Zealander came across as not only talented, but also as having major cojones.
So let's talk about the therapeutic that was tested by During and his colleagues. The researchers used an adeno-associated virus (AAV) to deliver a gene encoding the protein, glutamic acid decarboxylase (GAD), to the subthalamic nucleus in the brains of Parkinson's patients.
So what does that all mean? Well, let's briefly review AAV. AAV are small viruses that do not induce an immune response in humans. Additionally, they deliver DNA genetic material which directly incorporates into the cellular genome. It gets copied when transduced cells divide into daughter cells. Now we'll talk about Parkinson's Disease. Parkinson's is a complicated disease which results in neuronal death, neurodegeneration. Specific parts of the brain are very susceptible to this neurodegeneration. The substantia nigra of the brain is one of those parts. As a result the neurotransmitter balance is thrown off to the point where the substantia nigra is too "excited". The aim of a GAD gene therapy is to turn part of the substantia nigra from a primarily excitatory nucleus to a primarily inhibitory system.
Whether or not the gene therapy is working the way the researchers think it does is always up for debate. What isn't as debatable is the fact that most of the patients who received the injection of GAD encoding virus had symptomatic improvements. Since this was mainly a dose ranging and safety Phase I/II clinical trial, the number of patients was not high enough to power a statistically significant symptom amelioration metric. However, all signs point toward some hope for improved quality of life for Parkinson's patients. What this also provides is another glimmer of hope that gene therapy strategies might be in the clinic sooner than later. What this certainly is NOT is a cure. Patients need to remember that the neurons are still dying. Neurodegeneration is an extremely tough nut to crack (trust me on this one...I'm in neurodegeneration research for the long haul). Maybe one day we'll come up with a gene therapy that can protect the neurons...
There have been recent reports about a gene therapy strategy that resulted in symptom amelioration in Parkinson's patients. The project was spearheaded in part by Dr. Matthew During of Ohio State University. Having met Dr. During at the Society for Neuroscience conference in Orlando in 2002, I am not at all surprised that he would be part of a project that could stand at the cutting edge of clinical translational research. As a trained neurosurgeon with a PhD, this New Zealander came across as not only talented, but also as having major cojones.
So let's talk about the therapeutic that was tested by During and his colleagues. The researchers used an adeno-associated virus (AAV) to deliver a gene encoding the protein, glutamic acid decarboxylase (GAD), to the subthalamic nucleus in the brains of Parkinson's patients.
So what does that all mean? Well, let's briefly review AAV. AAV are small viruses that do not induce an immune response in humans. Additionally, they deliver DNA genetic material which directly incorporates into the cellular genome. It gets copied when transduced cells divide into daughter cells. Now we'll talk about Parkinson's Disease. Parkinson's is a complicated disease which results in neuronal death, neurodegeneration. Specific parts of the brain are very susceptible to this neurodegeneration. The substantia nigra of the brain is one of those parts. As a result the neurotransmitter balance is thrown off to the point where the substantia nigra is too "excited". The aim of a GAD gene therapy is to turn part of the substantia nigra from a primarily excitatory nucleus to a primarily inhibitory system.
Whether or not the gene therapy is working the way the researchers think it does is always up for debate. What isn't as debatable is the fact that most of the patients who received the injection of GAD encoding virus had symptomatic improvements. Since this was mainly a dose ranging and safety Phase I/II clinical trial, the number of patients was not high enough to power a statistically significant symptom amelioration metric. However, all signs point toward some hope for improved quality of life for Parkinson's patients. What this also provides is another glimmer of hope that gene therapy strategies might be in the clinic sooner than later. What this certainly is NOT is a cure. Patients need to remember that the neurons are still dying. Neurodegeneration is an extremely tough nut to crack (trust me on this one...I'm in neurodegeneration research for the long haul). Maybe one day we'll come up with a gene therapy that can protect the neurons...
State of the Art: GENE THERAPY- Pt2

See part 1
Viral Delivery
Most gene therapy strategies in research and clinical labs up until now have revolved around harnessing the evolved capabilities of viruses to deliver their viral genomes into cells. This is commonly known as use of a viral vector.
Let’s talk a little bit about viruses. Viruses are particles which can infect cells of living organisms. Viruses are made up of a protein shell encasing viral genetic material. In order to reproduce, viruses attach via their protein shells to cell surface membranes where they inject their genetic material. For normal disease causing viruses, the viral genetic material hijacks the cell’s protein and nucleotide generating machinery to produce more complete virus particles. The cycle continues until the immune system can seek and destroy the viral particles (unless the immune system is the target of the virus; as in the case of HIV). The process by which viruses deliver their viral genomes into cells is referred to as viral transduction.
In order to use a virus as a delivery vector, the viral genetic material basically needs to be removed and replaced with genetic material encoding the desired cellular product.
Retroviruses
There are a few different kinds of viruses which can be used for gene transduction. Retroviruses are one kind. Retroviruses store their genetic material in the form of RNA. When a retrovirus infects or transduces a cell, it introduces ins RNA and a few additional enzymes to the cell. The RNA is then copied to DNA inside the cell my an enzyme called reverse transcriptase. The new DNA is then inserted into the cell’s own genome by the integrase enzyme. The viral DNA is now a part of the host cell’s DNA. If the host cell divides, then any daughter cells will share the new DNA. The great thing about that from a gene therapy standpoint is the fact that there would be little or no need to introduce the therapeutic gene more than once. The downsides to it, however, are that:
1) The viral DNA can be incorporated into portions of the cell genome that result in faulty transcription of important genes. This could lead to cancer conditions caused by the gene therapy in the same way that human papillomavirus (HPV) predosiposes women for cervical cancer.
2) If the virus inserts itself into the wrong cell type, the genetic material could be passed on indefinitely within unintended cells for unintended results.
Adenoviruses
Adenoviruses are very different from retroviruses in that the genomic material which adenoviruses use to hijack a cell starts as DNA. Additionally, the DNA does not incorporate itself in the host cell’s genome. The viral DNA finds its way into the host cell’s nucleus where it is transcribed to RNA in the same way all nuclear DNA is transcribed. However, since the viral genes are not incorporated into the cell’s genome, the gene will not be duplicated and passed on to daughter cells after cell division. In one sense, this is advantageous from a gene therapists standpoint. It means that the gene product will only be produced as long as the transduced cells are alive. Long term side effects are minimal. The downside of this approach, however, is the fact that the virus would likely need to be administered more than once.
Adeno-Associated Viruses
The major downside to AAV is the fact that the viral particles are very small and cannot hold very much genetic material. They would be limited in what gene products they could code for.
So now you know the three types of viruses used for gene therapies. You also know their basic advantages and disadvantages. The next installment in this series will talk about non viral gene delivery techniques. After that, we will summarize the potentially therapeutic gene products being tested in contemporary research labs. We hope you are enjoying the content so far.
Thursday, June 21, 2007
State of the Art: GENE THERAPY- Pt 1
What is Gene Therapy?
Gene therapy is the term used for a biological treatment that is designed to introduce new active genetic material to living cells in order to increase or reduce a genetic product or products. These products can include either RNA or proteins or both. For the crudest of analogies, imagine the cell is a factory. This factory has assembly lines that currently build blenders. The blenders are great, but you also want to make toasters now. You send instructions to the factory to reconfigure some of its assembly lines to make toasters for at least part of the time. That is basically what is happening in gene therapy.
The most easily related example that I can think of where this technology could be useful is in Type I diabetes mellitus, where there is a deficiency in production of the protein, insulin, which is encoded by DNA on chromosome 11 in humans. An easy illustration of how a gene therapy could work would be to say that the gene for insulin production could be introduced to cells of a Type 1 diabetes patient so that their body would then be capable of generating insulin on their own. They would no longer need to take insulin shots to control high levels of blood sugar. I will stop there and now posit the emphatic caveat that the case of Type 1 diabetes is much more complex than I just described. The lack of insulin production is not because a gene is missing, rather it is because the cells that normally produce insulin are missing. In fact, diabetes might be better treated with a stem cell therapy than a gene therapy; but I digress (a topic for another State of the Art series). The main point of this ambling monologue is that, by using gene therapy, a new gene or genes can be introduced so that a cell can generate a product that it wasn’t previously generating in order to achieve a variety of net effects.
In the
While there are dozens of gene therapy clinical trials and hundreds of labs worldwide conducting research with gene therapy technologies, there is still no FDA approved gene therapy product on the market; nearly 17 years after the first human gene therapy trial was conducted on a 4 year old girl with severe combined immunodeficiency (SCID) at the U.S. National Institutes of Health in 1990.
Why are gene transfers so challenging to develop and administer? There are many pitfalls. First of all, it is simply difficult to incorporate new genes into living cells, especially in a multicellular tissue system. Secondly, once the gene is there, it doesn’t always produce an active protein (or RNA). Thirdly, if the gene does work, it is very difficult, if not impossible, to turn it off, thereby rendering overdoses and immune reactions virtually impossible to treat. Forthly, it is difficult to target genes to show up in the correct cells while not also affecting cells that don’t need the gene. Lastly, there are some questions about potential to pass on the therapeutic gene to offspring who won’t need it.
These issues are currently being addressed with variable success in research around the world. They are testing many different genes and gene deliver strategies in hopes of harnessing biology’s machinery to treat diseases. In the next installments of State of the Art: GENE THERAPY, we will talk about specifics of where the technology is right now. For now, chew on this one. Think of questions. Tell me I am an idiot. Thanks for reading. :)
Upcoming Posts!
Viral Delivery
State of the Art: GENE THERAPY- Pt3
Non-Viral Delivery
Wednesday, June 20, 2007
OMNOME in the Tangled Bank
Please take a moment to visit the 82nd installment of the weekly science blog carnival, Tangled Bank hosted at gregladen.com. It seems that each week, a different member of the science blog community writes a themed post while addressing and linking to recent pertinent posts from the science blog community. We've been informed that this week omnome.com's post about the ENCODE publication in Nature was included.
Greg Laden's post is very informative and entertaining. Take a look!
Greg Laden's post is very informative and entertaining. Take a look!
Tuesday, June 19, 2007
Welcome to OMNOME!
Welcome to www.omnome.com and thank you for reading. If you have already been frequenting our site, you’ve probably got some idea of what we’ll be talking about here.
We picked the name, OMNOME, because we wanted this project to broadly address, with varied levels of depth, the study of all sciences. Most of our topics will fall under three main categories: 1) Biology, 2) Physics, and 3) Mathematics. We understand that we can't be experts across such a diverse array of subjects, but we hope we can talk about what we know and learn accurately and articulately.
Most articles will stand alone, but we will also regularly publish segments in a “State of the Art” series which will describe where general classes of technologies such as nanoparticles, gene therapies, stem cells, and fiber optics currently stand.
Finally, you might be wondering about the “sheep” theme of the site. We picked it as a homage to Dolly, the cute clone sheep. Dolly’s arrival in 1996 ushered in a maelstrom of news coverage which told us that Dolly would either cure diseases or lead humanity into an ethical crisis. Neither of those scenarios proved to be immediately true while potential still exists for both to become true in time. Much science coverage today follows the same model of conveying hope and fear simultaneously. We hope that we can cut through a little bit of the hyperbole in the coverage and help you get a clearer picture of what is going on in the research labs of the world.
Sunday, June 17, 2007
EARTH II: How to Find Earth-like Planets

There has been a lot of press lately about the discoveries of many “Earth-like” planets outside of our solar system orbiting other stars, otherwise known as terrestrial exo-planets. When I read press releases about these things, I picture exotic worlds filled with oddly colored vegetation, some animal like creatures, and maybe skinny humanoid biped extraterrestrials
with some intelligence and language. I also wonder how long before humans can colonize.
Then I remember that I am probably getting way ahead of myself and I start asking annoying questions like:
- What is the definition of an “Earth-like” exo-planet?
- What technologies are scientists using to discover exo-planets?
- What technologies are scientists using to discover the nature of these planets?
What do scientists mean when they call a planet “Earth-like”?
Historically, an Earth-like, or terrestrial, planet has been characterized as a rocky planet like Earth or Mars, as opposed to a gas giant like Jupiter. However, recent news articles seem to be adding an additional element to the vernacular connotation of “Earth-like”; they seem to be talking about rocky planets that are the same distance from their star as we are from our sun. The basic implication here is that scientists are trying to find environs that might be adequate or ideal to support life; like the our home planet Earth.
The most interesting thing to note about the definition of “Earth-like”planet is that it is a very broad definition. A planet exactly like Mars in another solar system would easily fall under the definition. As we all know, Mars is hardly lush with tropical rainforests.
What technologies are scientists using to discover exo-planets?
Right now, scientists can’t see these planets directly through conventional light telescopes, not even with the amazing Hubble Space Telescope without first knowing exactly where to look. This is because the planets are not bright or big enough relative to their cosmic surroundings to stand out. In the same way that ambient city lights make it difficult for us to distinguish stars in the night sky, bright stars make it very difficult for us to distinguish nearby planets in the night sky even with high powered telescopes. Because of this, scientists need to be creative when discovering distant non-star celestial bodies.
Most exo-planet discovery has been accomplished with a technique called gravitational microlensing. Gravitational microlensing harnesses one of clever Albert Einstein’s equations predicting the nature of light and gravity. Einstein predicted that light observed from a distant source, like a bright star, would bend whenever a massive object passes near the light beams between the source and observer. Not surprisingly, Einstein was right and scientists can use these light bends to determine when planets are passing between stars and us. Depending on how big the star is, scientists can use the degree of light bending to determine how big an orbiting planet is.
What technologies are scientists using to discover the nature of exo-planets?
Basically, gravitational microlensing can indicate the presence of a planet and a little bit about its mass. Once we know where a planet is, we can point high powered telescopes at it in order to catch a glimmer of its reflected light. Once we can observe the reflected light, we can learn more about a planet’s orbit using another indirect observation technique called radial velocity analysis.
To explain radial velocity analysis, we will talk a little bit about the nature of light. Light travels in waves with specific wavelengths for each color of light. Longer wavelengths look redder and shorter wavelengths look bluer. Another one of Einstein’s clever insights was that if a light source, in this case a planet, was moving toward you, its light wavelength would shorten and look then look bluer. When it is moving away, it will look redder. Because of this we can determine the distance and duration of a planet’s orbit. This is how, besides knowing a planet’s size, scientists can determine how far it is from parent star.
When will we know more?
In general, all we can really know about the exo-planets right now are the following characteristics:
- That the planet is there.
- How big it is
- How close it is to its sun
- How fast it moves
Because of those facts, we can guess what the planet is made of and how hot or cold it is.
We will know much more within the next decade when NASA launches its Terrestrial Planet Finder project into space and when ESA launches its
We have a ways to go, but maybe someday will finding ourselves looking at someone who is looking back at us. Well, because of the speed of light it would mean they were looking at us about 30 years ago and we are just seeing them now.
Thursday, June 14, 2007
What did ENCODE decode?

As recently as five days ago, I penned a post about what the Human Genome Project (HGP) had and had not accomplished. I wish I could say that I had written that with the full knowledge that it would be a great primer for a piece about the genome discoveries released today by ENCODE , the NIH follow-up effort to the HGP. I would be lying if I did.
Anyways, front and center at Nature.com is a pdf of the publication by the Encode Consortium outlining the highlights of their efforts to pass a fine toothed comb through approximately 1% of the human genome.
The publication is fascinating in both its breadth and detail. Before I expound on its virtues, let me first comment on my only suspicion about the project. From my own somewhat limited experience in biomedical research, I am not a big fan of large consortium efforts. While I love the concept of open source sharing of data and collaboration, I have usually found that huge efforts across many labs breed data inconsistencies as a result of methodological and analytical differences. Differences in variables as small as humidity in the lab can yield differences in datasets that can obscure the real story. All of that said, it would be very hard to argue with the key points that are coming out of this publication, because the key points make a lot more sense than the conventional wisdom that has been coming out of college biology text books for years (at least when I was in college).
Most of us have been taught at some point that DNA leads to RNA which leads to protein. Well, all of that is still true, but as time goes on, we continue to discover that there are more and more options for the RNA besides producing protein. Without further ado, here are the take home notes on the ENCODE project:
- While it was once thought that a large proportion of DNA was "junk" which did nothing, it is becoming clearer that the vast marority of DNA does transcribe RNA. Many new non-protein coding RNA's have been discovered in the ENCODE effort.
- Chromatin accessibility, basically how tightly the DNA is wound, has a huge effect on how readily it is transcribed to RNA. In turn, many RNA's can affect how tightly the DNA is wound.
- We have evolved in a way that has rendered about 5% of our DNA inactive.
- Some regions of our DNA are wildly variable from person to person, while other regions barely change (this isn't really news, but they've been able to pinpoint some of the specific variable regions).
- RNA can do many things beside encode for protein. Some RNA's are used by the cell to suppress other RNA's...thereby regulating the genome. (this isn't really news either).
- There is way too much RNA in cells for us to know what all of it does at this point in time
Wednesday, June 13, 2007
AVIAN FLU- Will it ever take off?

A while back, there was a huge media scare about the avian flu. Media fear mongering alternately amuses and irritates me. The media often fills news gaps with whatever they can come up with that might terrify the populace and incite us to improve their ratings and sales. Perhaps one day we can write an article about the psychology behind scare tactics in media programming. Today, however, I am going to talk about the avian flu and the flu in general.
How much do each of us really know about the flu? Before I started my formal medical education, I could barely tell the difference between having the flu and having a bad cold myself. They are both viruses. Both result in the symptoms which can include sore throats, coughing, achiness, and headaches.
So what are the differences? Well, first of all, cold’s are caused by rhinoviruses. As the name implies, rhinoviruses cause symptoms in the nose. That snotty, nasal congestive hell that we all go through at least once yearly can be blamed on the common cold. Generally speaking, the common cold stays in the upper respiratory tract. The flu, or influenza as it is more formally known, is caused by the orthomyxoviridae family of viruses. While some of its symptoms are shared with the common cold, it is noted for knocking us completely out of commission for a day or two. All we can do is just lay in bed and whine to our significant others. In the worst cases, the flu can cause pneumonia. For those of you who have never experienced this fun condition, it’s a lot like drowning in your own mucous. It can be fatal, especially in very young or very old patients. Not fun.
That’s right, most flu viruses that infect humans are originally avian viruses. Then why the big deal about this new avian flu? Well, it seems that this particular strain, the H5N1 strain, of avian flu is quite deadly when contracted by humans. Fortunately for our species thus far, though we can contract the virus directly from birds, we cannot pass the virus on to other humans.
As CNN, FoxNews, and Katie Couric have all informed us many times, many leading epidemiologists believe that it will only be a matter of time before the H5N1 strain mutates into a form by which humans can infect each other directly. Mass hysteria will follow. Everyone will dress up in football pads and have Mohawks like they did in the post apocalyptic world of Mad Max. It’ll be great. Really.
Just kidding. We won’t be wearing football pads.
Then stay as far away from public transportation and airports as you can possibly get.
Monday, June 11, 2007
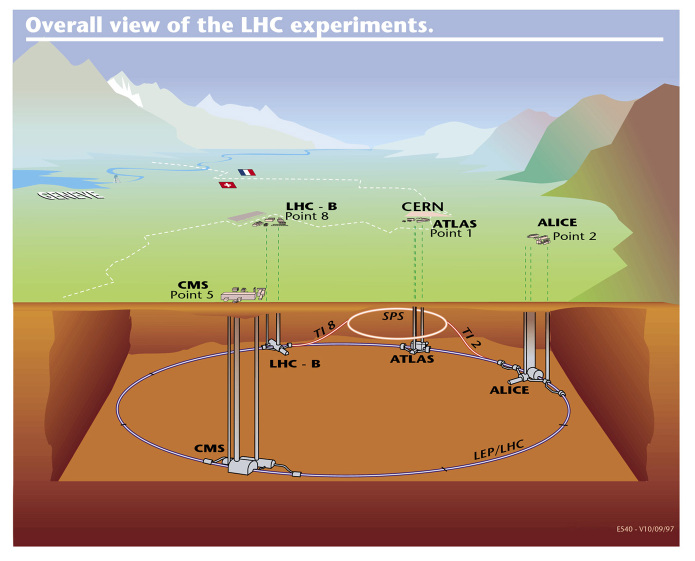
CERN's LARGE HADRON COLLIDER- A Big Hit?
 You may have recently read in the newspaper or seen television news reports about a brand new particle accelerator in
You may have recently read in the newspaper or seen television news reports about a brand new particle accelerator in What could anyone possibly mean when they say “Theory of Everything”?
In day to day life, the word theory usually implies conjecture. It is typically a proposed explanation for an unsolved mystery. In science, however, a theory is a mathematic or logical explanation that can be used to reliably predict the outcomes of similar future occurrences. For example, the Theory of Gravity allows us to predict that an apple will fall to the earth. It also tells us that a satellite, if it is traveling fast enough, will orbit the earth. I suppose the apple, if it traveled fast enough, could also orbit the earth; but I digress.
So if theories are supposed to predict similar future occurrences, does it follow that a “Theory of Everything” should predict, well, everything? Sort of.
What physicists aspire to attain in a “Theory of Everything”, or unified theory, is a theory that can account for the force gravity into the mostly reconciled theories of quantum mechanics (really small subatomic stuff) and special relativity (E=mc^2).
Would a unified theory help you predict how your boss will react to your hangover tomorrow? Probably not. In that sense, it isn’t a theory of everything. However, it would make it possible to understand a least a bit more about how our universe began and where we fit into it. On a more practical level, in the same way Einstein’s theories led to nuclear power and space travel, mankind will likely experience similar benefits (and possibly detriments) as a result of any unified theory discovery.
Many possible unified theories have been proposed, the most popular of which are the many variations of String Theory. Unfortunately, much to the consternation of many physicists and other curious observers, up until now the theories have been mostly untestable. That brings us to why that particle accelerator/collider in
Brought to you by the inventors of the internet, CERN (The European Organization for Nuclear Research) presents the Large Hadron Collider (LHC)!
What are Hadrons and why will colliding them help lead to a “Theory of Everything”?
In 1995, the CERN Council approved the construction of the world’s largest subatomic particle accelerator and collider to be funded by CERN’s 20 member states. The multibillion euro (or dollar) effort has resulted in a collider housed in a 17 mile circumference tunnel crossing the French/Swiss border twice that sits as far as 450 feet underground.
Simply put, the tunnel contains two pipes that are designed to shoot beams of tiny subatomic particles, broadly referred to as hadrons, but mainly in this case the more commonly known protons, directly at each other in order to observe their interactions before, during, and after moment when the beams collide.
What type of information could come out of proton collisions? Well, it can be explained in a small way by addressing the now universally known equation: E =mc^2. That is to say that Energy = mass * the speed of light squared. By accelerating hadrons at each other to speeds approaching the speed of light, the hadrons will acquire very very high energy levels. The energy released during the particle collision will theoretically generate subatomic particles of masses never before observed by humans. These theoretical particles, often referred to as Higg’s Bosons (alias: God Particle), and their properties are expected to fill gaps in current theories. Physicists hope that the gravity force will finally fit into current understandings of quantum mechanics and relativity.
Looking Back in Time
Many scientists believe that the high energy proton collisions generated by the LHC will replay the moments immediately after the “Big Bang” inception of the universe. Some have gone so far as to call the LHC a time machine. Personally, I think that is a pretty lame comparison. The LHC will no more carry as back in time to the Big Bang than a Battle of Gettysburg reenactment takes us back in time to the Civil War. I think the metaphor preys on the sensibilities of us sci-fi geeks who dream of flux capacitors and warp drives. However, what is important to note is that it is possible that the only way for us to understand the underlying nature of the present state of the universe might be for us to understand its nature at its beginnings.
When Will We Know?
Just last month in May of 2007, press releases told us that the accelerator was virtually completed and that the first experiments to unlock the secrets of the universe would be conducted during the summer of 2007. As recently as last week, however, CERN announced that the experiments would be put off until 2008 because a confluence of minor problems across much of the new equipment.
Some doomsday alarmists don’t mind the delay. Some believe that the LHC at CERN will generate a black hole or some other “un”natural manifestation which will destroy the world or maybe even the universe. While the concept would be great for a Dan Brown book about a lone scientist trying to avert global/universal destruction, most of us can choose to rest easy. Experiences with other colliders in the past seem to indicate that any problems with the experiments can be contained neatly below ground.
Saturday, June 9, 2007
HUMAN GENOME PROJECT- Where is it now?
Let me start by acknowledging that the international public Human Genome Project (HGP) and the private Celera Genomics enterprise achieved a monumental task in sequencing the human genome in 2001. News media outlets trumpeted the accomplishment with verbal steamers and confetti, calling it, among other superlatives, “the Rosetta Stone of Life.” Press releases and magazine features foretold of new disease diagnostics, treatments, and even cures which would emerge from having “decoded” the blueprint for human life while warning about the ethical fallout that could emerge from DNA manipulation.
What They Forgot to Mention
The media outlets were mostly right. They, along with the scientists and the public relations professionals involved with the projects, told us that the sequencing of the human genome was the first step toward understanding and treating many human diseases. What they didn’t tell us was how many additional steps would still need climbing before we would reap those rewards. It seems that what the project yielded was far less “Rosetta Stone” and far more akin to the discovery of a tomb filled with unintelligible Egyptian hieroglyphs.
Many articles describing the HGP erroneously use the words “sequenced” and “decoded” interchangeably. In fact, Wikipedia describes the HGP as “a project to decode (i.e. sequence) more than three billion nucleotides contained in a haploid reference human genome and to identify all the genes presented in it.” The fact is, “decode” and “sequence” are quite different.
What Did the Human Genome Project Accomplish?
If by sequencing the human genome, the HGP and Celera didn’t actually decode it, then what exactly did they accomplish? To explain, we must first take a cursory look at the ingredients that make up the genome, deoxyribonucleic acid (DNA). DNA basically is made of chains of molecules called nucleotides. There are four different nucleotides which make up DNA. These are cytosine (C), thymine (T), adenine (A), and guanine (G). The HGP and Celera looked at the complete genome of one man and cataloged each of his 3 billion plus nucleotides. Basically, the hullabaloo in 2001 was simply the media fanfare that accompanied the inking of the correct order of a single human’s C’s, T’s, G’s, and A’s.
How will this correctly ordered catalog of letters eventually result in disease diagnostics and treatments? It will be a long and winding path along which the science community has only taken a few short steps. After having laid out the map of one man’s genome, researchers are now laying out the genomic maps of many others. In order to learn what each of the 30,000 genes does, researchers must compare the genomes of many humans, determine which nucleotides are ordered differently and how those differences in nucleotides translate into differences in how we each look, behave, grow, age, develop diseases, fight off diseases, and so forth. Objectively speaking, the cataloging of that first genome is no more valuable than any of the genomic catalogs which have followed; or will follow. The mapping of the first genome was a huge milestone, but any one of us could currently have our entire genomes mapped in the exact same way for a cost of approximately $200,000. The information obtained from your genome would have the same research value as the information gleaned from the entire multibillion dollar international effort of the HGP and Celera less than a decade ago.
Where will the Human Genome Project take us?
Research projects, like the international HapMap Project, are currently cataloging and comparing the genomes of humans across relatively tight clusters of human populations. We are learning what the predominant differences in the genetic codes of four distinct populations of African, Asian, and European ancestry. With each of the populations representing variable risk factors for specific diseases and conditions, these comparisons could provide indications of which genes can lead to diseases or protect against diseases (this effort is a minefield of unresolved ethics issues…a topic for another post).
Efforts to take advantage of the ability to map each of our genomes are further confounded by the fact that our genetic codes represent only a small portion of the complexities of our molecular biological systems. The HGP tells us that we have approximately 30,000 genes. Suppositions before the Genome project were that each single gene encodes a single protein . We are left now to wonder how humans are built of approximately 120,000 proteins. To explain this, it must be the case that some genes can be toggled to create more than one gene product. The toggling must be controlled by other genes which might also be “toggle-able”.
In the end, like the first moon landing in 1969, the accomplishments of the Human Genome Project represent a huge milestone for humanity. Also, like the first moon landing which only represented a tiny step out into the unfathomable depths of our galaxy, the mapping of the human genome is only a tiny step into the unfathomable complexities of biology and life itself.
Subscribe to:
Posts (Atom)




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}